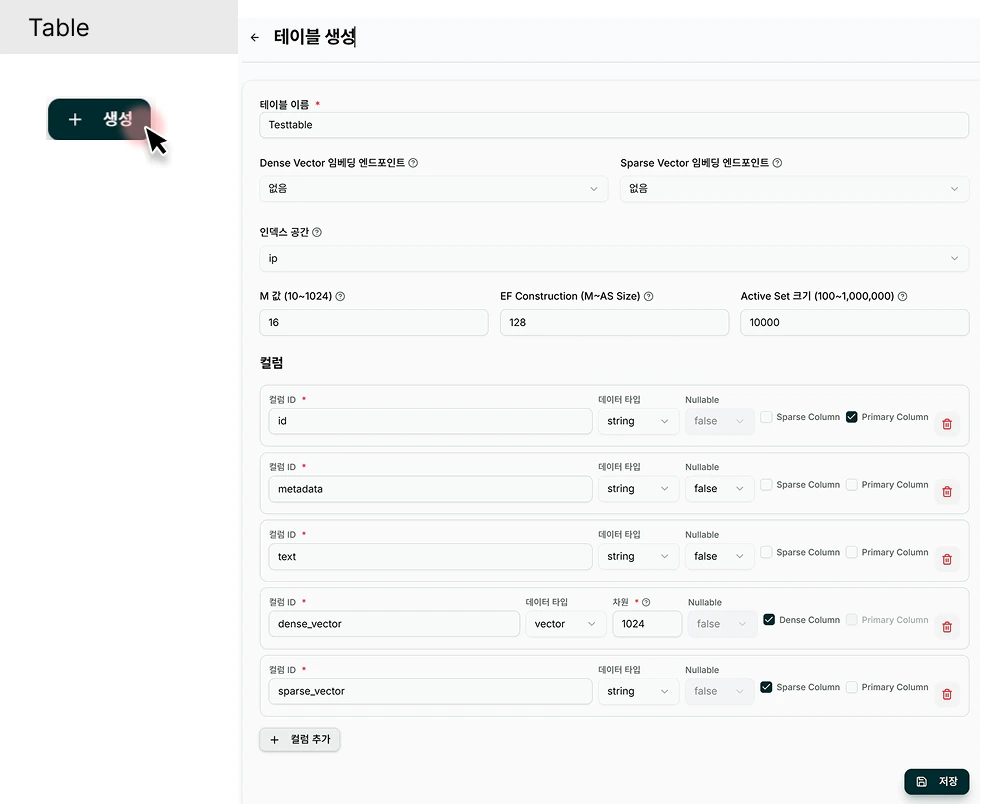
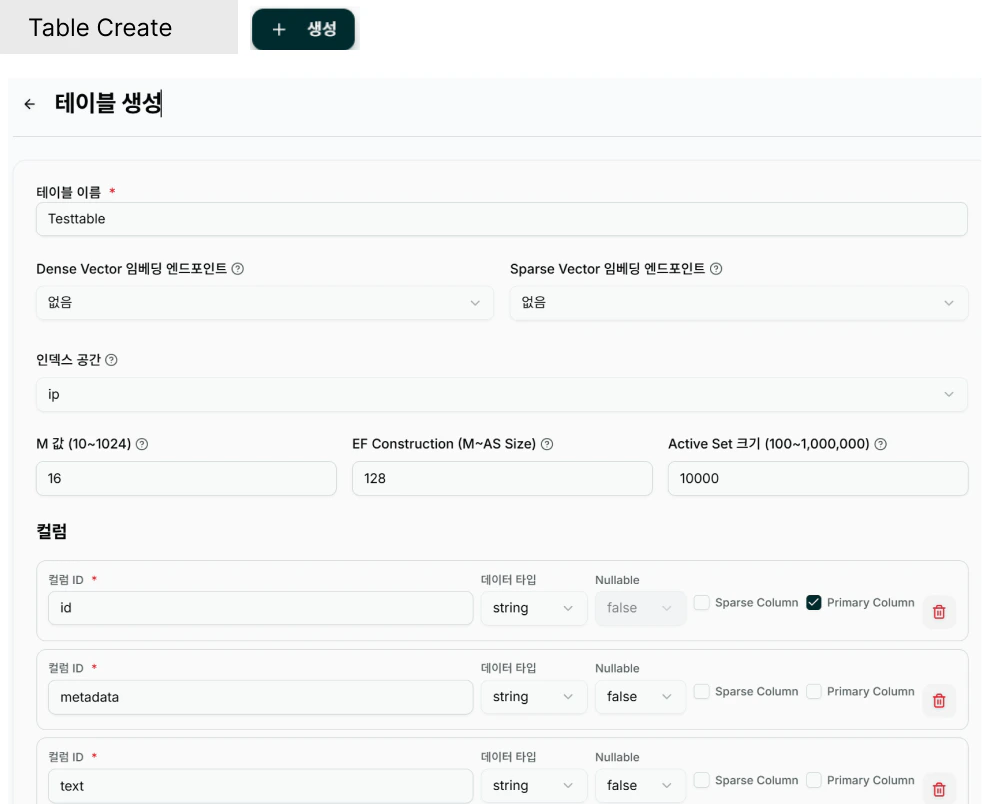
Table 생성
경로: “Database” > “Tables” > “Create Table” Tables 화면에는 현재 클러스터에 생성된 모든 테이블 목록이 표시됩니다.기본 정보 입력
| 필드명 ( 화면 표시 ) | 설명 | 타입 | 필수 | 예시 |
|---|---|---|---|---|
| TABLE NAME | 테이블의 고유 이름 길이 : 64자 제한 String | TextField | 필수 (*) | my-table |
| Dense Vector Embedding | Dense Embedding은 텍스트를 고정 길이의 밀집 벡터로 변환합니다. 의미적 유사도 검색의 핵심이며, 문맥과 의미를 포착합니다. | Dropdown | 선택 | DNA 2.0 *운영자 세팅에 따라 달라집니다. |
| Sparse Embedding | Sparse Embedding은 키워드 기반의 희소 벡터를 생성합니다. Dense와 결합하여 하이브리드 검색을 가능하게 하며, 정확한 키워드 매칭에 강점이 있습니다. | Dropdown | 선택 | DNA 2.0 *운영자 세팅에 따라 달라집니다. |
Tablel Name
테이블의 식별 이름을 입력합니다 Validation :- name : 필수 입력 64자 제한
- a-z, A-Z, 숫자, 하이픈(-) 허용
- 하이픈 시작/종료 불가
- 영문으로만 시작 가능
- 이름 중복 생성 가능 : 필요시 UUID로 구분이 가능합니다.
- 테이블 이름은 생성 후 변경할 수 없으므로 신중하게 결정하세요
- 버전 관리가 필요하면 이름에 버전을 포함하세요 ( 예 : embeddings-v1, embeddings-v2
Dense Vector
Dense Embedding은 텍스트를 고정 길이의 밀집 벡터로 변환합니다. 의미적 유사도 검색의 핵심이며, 문맥과 의미를 포착합니다.Sparse Vector
Sparse Embedding은 키워드 기반의 희소 벡터를 생성합니다. Dense와 결합하여 하이브리드 검색을 가능하게 하며, 정확한 키워드 매칭에 강점이 있습니다.INDEX 설정 (인덱스 공간)
| 필드명 ( 화면 표시 ) | 설명 | 타입 | 필수 | 예시 |
|---|---|---|---|---|
| INDEX SPACE | 벡터 간 유사도 계산 메트릭 — - l2space : L2 Distance (Euclidean, 절대 거리 ) — - ipspace : Inner Product ( 내적 , 방향 + 크기 ) | Dropdown | 필수 | ipspace |
| M VALUE | HNSW 연결 밀도 — - 높을수록 정확도 증가 , 메모리 사용 증가 — - 권장값 : 16 | Number (10~1024)범위의 정수 | 필수 | 16 |
| EF CONSTRUCTION | 인덱스 구축 품질 — - 높을수록 인덱스 품질 향상 , 구축 시간 증가 — - 권장값 : M Value~ Active set size | Number (M Value~ Active set size) | 필수 | 128 |
| ACTIVE SET SIZE | 메모리에 동시 로드 가능한 벡터 개수 — - 인덱스의 메모리 캐시 크기 — - LRU 방식 관리 | Number (100~1,000,000) | 필수 | 50000 |
| Segmentation Buckets | 해시 세그멘테이션 버킷 수 (기본값: 1)수 — - 데이터를 분산 저장할 버킷 수입니다. 해시 세그멘테이션을 활성화하여 대용량 데이터의 병렬 처리 성능을 향상시킵니다. | Number (1~10) | 필수 | 1 |
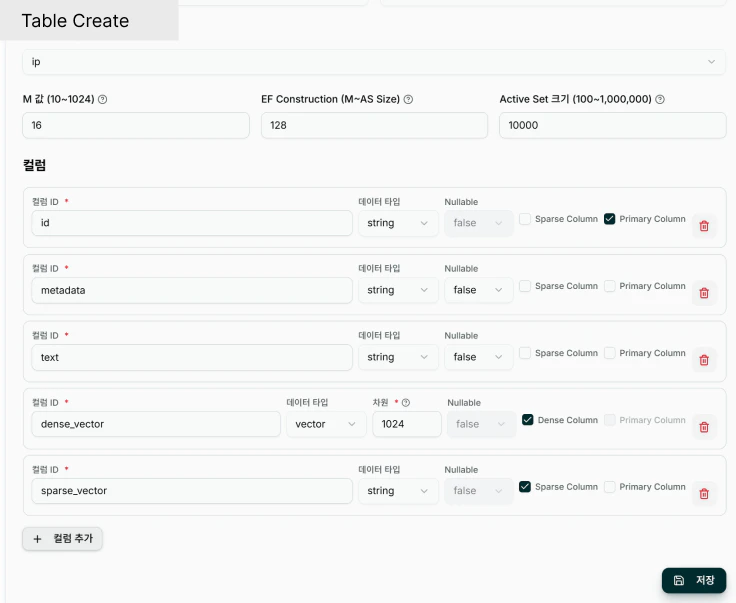
INDEX Space
- 벡터간 유사도를 계산하는 거리 메트릭을 선택합니다 .
| Index Space | 계산 방식 | 범위 | 특징 | 적합한 데이터 |
|---|---|---|---|---|
| l2space | L2 Distance (Euclidean) | 0 ~ ∞ (0 에 가까울수록 유사 ) | 절대 거리 계산 , 벡터 크기에 민감 | 이미지 특징 , 좌표 데이터 , 정규화되지 않은 벡터 |
| ipspace | Inner Product ( 내적 ) | -∞ ~ ∞ ( 클수록 유사 ) | 벡터 크기와 방향 모두 고려 | 텍스트 임베딩 , 추천 시스템 , 정규화된 벡터 |
M value
- HNSW 인덱스의 그래프 연결 밀도를 설정합니다 .
- 의미 :각 노드가 연결할 이웃 노드의 개수
- 범위 : 1 ~ 1024 범위의 정수
- 권장값: 16
- 높을수록 :정확도증가 ,메모리사용 증가 ,검색 속도 약간 감소
- 낮을수록 :메모리사용 감소 ,정확도감소*
EF CONSTRUCTION (인덱스 구축 품질)
- 인덱스 구축 시 탐색할 후보 노드 수를 설정합니다 .
- 의미 : 인덱스 구축 시 탐색할 이웃 노드의개수
- 범위 : M value 값 이상 ACTIVE SET SIZE 이하의 정수
- 권장값 : 128
- 높을수록 : 인덱스 품질 향상 , 구축 시간 증가
- 낮을수록 : 구축 시간 감소 , 인덱스 품질 저하
ACTIVE SET SIZE (활성 벡터 제한)�
- 메모리에 동시에 로드할 수 있는 벡터 개수의 최대값입니다 .
- 의미 : diskbased 인덱스에서 메모리 캐시 크기 결정
- 범위 : 100 이상 1,000,000 이하의 정수
- 기본값 : 50000
COLUMNS ( 스키마 정의 )
테이블에 저장할 데이터의 구조를 정의합니다 . 각 컬럼의 이름 , 데이터 타입 , 제약 조건을 설정합니다.| 필드명 ( 화면 표시 ) | 설명 | 타입 | 필수 | 예시 |
|---|---|---|---|---|
| COLUMN ID | 컬럼의 고유 이름 — - 길이 : 1~64 자 — - 허용 문자 : 영문 소문자 , 숫자 , 언더스코어 (_) — - 영문으로 시작 — - 중복 불가’Duplicate column name exists.’ 메세지 발생 | TextField | 필수 (*) | id, text, embedding |
| DATA TYPE | 컬럼 데이터 타입 — - string : 문자열 — - vector : 벡터 ( 부동소수점 배열 ) — - int64 : 64 비트 정수 — - double : 64 비트 부동소수점 — - boolean : 불리언 | Dropdown | 필수 | string, vector |
| Nullavle | 데이터 필수 여부 확인 — - Sparse Column, Dense Column 응 기준이 되는 컬럼이면 비활성화 | Dropdown | 필수 | false, true |
| DIMENSION | 벡터 차원 수 — - vector 타입일 때만 표시 — - 16의 배수여야함 - 범위 : 1~65536 — - 모델 출력 차원과 정확히 일치해야 함 | Number (1~65536) | vector 타입 시 필수 | 1024, 1536, 768 |
| Sparse Column | 최대 1 개만 선택 가능 ( 라디오 버튼 동작 ) — - 체크된 컬럼이 Sparse 벡터 검색 대상 | Checkbox | 선택 | (embedding 컬럼 ) |
| Dense Column | vector 타입일 때만 활성화 — - 최대 1 개만 선택 가능 ( 라디오 버튼 동작 ) — - 체크된 컬럼이 벡터 Dense 검색 대상 | Checkbox | 선택 | (embedding 컬럼 ) |
| PRIMARY | Primary Key 컬럼 지정 — - string 타입일 때만 활성화 — - 최대 1 개만 선택 가능 ( 라디오 버튼 동작 ) — - 고유성 보장 , 행 식별용 | Checkbox | 권장 | (id 컬럼 ) |
기본 칼럼 구조
테이블 생성 시 다음 4 개 컬럼이 자동으로 생성됩니다 :| col_id | data_type | dimension | is_primary | ANN |
|---|---|---|---|---|
| id | string | 0 | true | - |
| metadata | string | 0 | false | - |
| text | string | 0 | false | - |
| embedding | vector | 1024 | false | 체크 |
| 동작 | 설명 | 결과 |
|---|---|---|
| 새 컬럼 추가 | 빈 컬럼 행 생성 | |
| Delete | 컬럼 삭제 | 해당 컬럼 제거 ( 최소 1 개는 남아야 함 ) |
| DATA TYPE 변경 | 데이터 타입 변경 시 | - vector → 다른 타입 : DIMENSION 자동 0 으로 초기화 , ANN 해제 — - 다른 타입 → vector: DIMENSION 필드 표시 |
| PRIMARY 선택 | 다른 컬럼의 PRIMARY 체크 | 이전 PRIMARY 자동 해제 ( 라디오 버튼 동작 ) |
| ANN 선택 | 다른 컬럼의 ANN 체크 | 이전 ANN 자동 해제 ( 라디오 버튼 동작 ) |
COLUMN ID* (컬럼 이름)�
컬럼의 고유 식별이름을 입력합니다. 입력 규칙 :- 필수 입력 64자 제한
- a-z, A-Z, 숫자, 하이픈(-) 허용
- 하이픈 시작/종료 불가
- 이름 중복 생성 가능 : 필요시 UUID로 구분이 가능합니다.
- 영문으로만 시작 가능
- 중복 이름 불가 ’Duplicate column name exists.’ 메세지 발생
DATA TYPE* (데이터 타입)�
컬럼에 저장될 데이터의 타입을 선택합니다 . 선택 가능한 데이터 타입 :| Data Type | 설명 | 예시 값 | 저장 크기 | 용도 |
|---|---|---|---|---|
| string | 문자열 | ” hello ”, “2023-10-17” | 가변 | 텍스트 , ID, 메타데이터 |
| vector | 벡터 ( 부동소수점 배열 ) | 고정 ( 차원 × 4 bytes) | 임베딩 벡터 | |
| int64 | 64 비트 정수 | 123, -456, 0 | 8 bytes | 숫자 ID, 카운트 |
| double | 64 비트 부동소수점 | 3.14, -0.001, 1e-5 | 8 bytes | 실수 , 점수 , 확률 |
| boolean | 불리언 ( 참 / 거짓 ) | true, false | 1 byte | 플래그 , 상태 |
DATA TYPE 상세 설명
String (문자열)
특징 :- 가변 길이 : 1 글자 ~ 수 MB 까지 저장 가능
- UTF-8 인코딩 : 한글 , 중국어 , 이모지 등 모든 유니코드 지원
- 인덱스 불가 : 벡터 검색 인덱스에는 사용할 수 없음 ( 메타데이터로만 사용 )
- JSON 데이터는 문자열로 저장하고 , 애플리케이션에서 파싱하세요
- 날짜 / 시간은 ISO 8601 형식으로 저장하세요 : “2023-10-17T14:30:00Z”
VECTOR (벡터)�
특징 :- 고정 차원 : 생성 시 지정한 차원 수만 저장 가능
- float32 정밀도 : 각 요소는 32 비트 부동소수점
- ANN 검색 가능 : 벡터 검색 인덱스 구축 가능
- vector 타입 선택 시 DIMENSION 입력 필드가 활성화됩니다
- 벡터 차원 수를 입력해야 합니다 (1~65536)
- DIMENSION 은 테이블 생성 후 변경할 수 없습니다
- DIMENSION 은 16의 배수로 설정되어야 합니다.
INT64 (64비트 정수)�
특징 :- 범위 : -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807
- 정수만 저장 : 소수점 없음
- 고정 크기 : 8 bytes
- ID 가 숫자인 경우 int64 사용 권장 (string 보다 효율적 )
- 카운트 , 순위 , 타임스탬프 등에 적합
DOUBLE (64비트 부동소수점)�
특징 :- 범위 : ±1.7E±308 (15~17 자리 정밀도 )
- 소수점 저장 : 실수 값
- 고정 크기 : 8 bytes
- 통화 , 점수 , 좌표 등에 적합
- 매우 작은 값이나 큰 값도 저장 가능
BOOLEAN (불리언)�
특징 :- 값 : true 또는 false
- 고정 크기 : 1 byte
- 플래그 , 상태 표시에 적합
- 필터링 조건으로 자주 사용됨
DIMENSION (벡터 차원 수)�
vector 타입 컬럼에서만 활성화되는 필드로 , 벡터의 차원 수를 지정합니다 . 표시 조건 :- Data Type = vector 일 때만 표시됨
- Data Type ≠ vector 이면 자동으로 숨겨지고 값이 0 으로 초기화됨
- 최소값 : 1
- 최대값 : 65536
- 권장값 : 사용하는 임베딩 모델의 출력 차원과 동일
ANN COLUMN (ANN 검색 인덱스 컬럼)�
주로 검색에 사용될 벡터 컬럼을 지정합니다 . 표시 조건 :- Data Type = vector 일 때만 체크박스 활성화
- Data Type ≠ vector 이면 비활성화
- 최대 1 개만 선택 가능 : 라디오 버튼처럼 동작
- vector 타입 컬럼만 선택 가능
- 선택 사항 : 현재 버전에서는 필수가 아님
- 벡터 검색 인덱스 구축 대상
- 시맨틱 검색 시 사용되는 벡터
- ANN 컬럼은 주로 검색에 사용될 벡터를 지정합니다
- 일반적으로 embedding 컬럼을 ANN 컬럼으로 설정합니다
- ANN 컬럼으로 지정하지 않은 vector 컬럼도 저장은 가능하지만 검색 인덱스는 구축되지 않습니다
- 현재 버전에서는 ANN 컬럼 선택이 선택사항입니다’
- 벡터 검색을 사용하려면 반드시 ANN 컬럼을 지정해야 합니다
PRIMARY Column (기본 키)��
각 행을 고유하게 식별하는 컬럼을 지정합니다 . 표시 조건 :- Data Type = string 일 때만 체크박스 활성화
- Data Type ≠ string 이면 비활성화
- 최대 1 개만 선택 가능 : 라디오 버튼처럼 동작
- string 타입 컬럼만 선택 가능
- 권장 : 정확히 1 개의 PRIMARY 컬럼 설정
- 고유성 보장 : 중복된 값을 가질 수 없음
- 행 식별 : UPDATE, DELETE 작업 시 사용
- 인덱스 자동 생성 : 빠른 조회 가능
- 고유성 보장: 중복된 값을 가질 수 없음
- 행 식별: UPDATE, DELETE 작업 시 사용
- 인덱스 자동 생성: 빠른 조회 가능