> ## Documentation Index
> Fetch the complete documentation index at: https://manual.seahorse.dnotitia.ai/llms.txt
> Use this file to discover all available pages before exploring further.
> Analytics — DuckDB 기반 데이터 분석 + VLM 문서 인덱싱. Tables / Indexed Documents 2 영역 + 11 개 도구 선택
# Analytics
# Analytics
**경로**: 하단 툴바 **Analytics**
DuckDB 기반 **인메모리 분석 엔진** + VLM(Vision-Language Model) 문서 인덱싱. CSV·XLSX·Parquet 을 테이블로 로드해 SQL 로 분석하고, PDF·DOCX·PPTX 를 **고품질 파서** 로 인덱싱해 시맨틱 검색에 활용합니다.
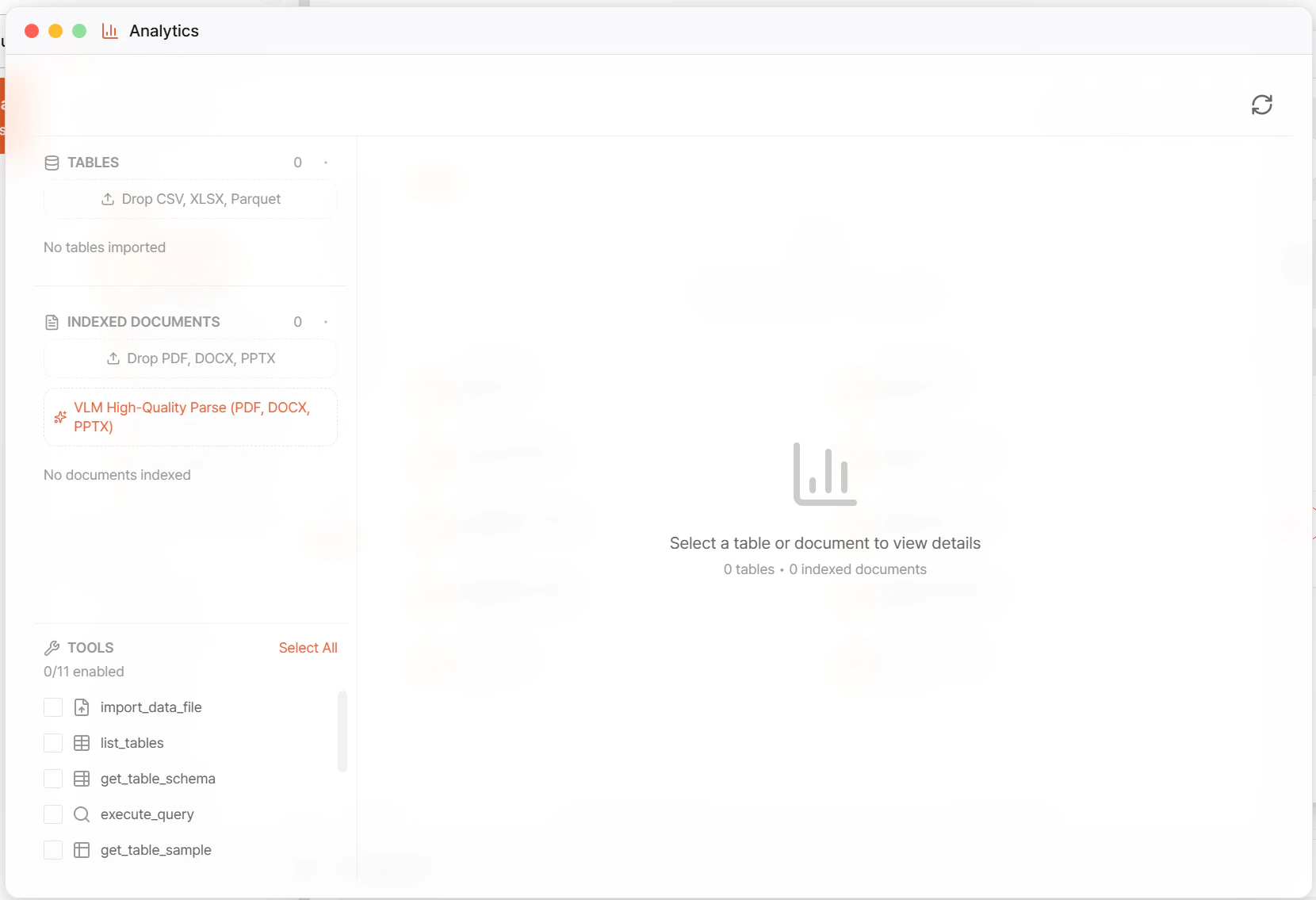 ## UI 구성
| 영역 | 설명 |
| ----------------------------- | ---------------------------------------------------------------- |
| **Tables** 섹션 | 업로드된 정형 테이블 — `Drop CSV, XLSX, Parquet` 드롭 존 |
| **Indexed Documents** 섹션 | 인덱싱된 비정형 문서 — `Drop PDF, DOCX, PPTX` 드롭 존 |
| **VLM High-Quality Parse** 토글 | ON 시 Vision Parser 로 고품질 인덱싱 (표·레이아웃 보존) |
| **Tools** 체크리스트 | 활성화할 도구 선택 (`N/11 enabled`) |
| 상태 라인 | `7 tables • 0 indexed documents` 형태로 요약 |
| 우측 패널 | `Select a table or document to view details` — 선택 시 스키마·샘플·메타 표시 |
## Tables 섹션
업로드된 정형 데이터 테이블 목록. 각 테이블에 **행 수** 가 뱃지로 표시됩니다.
| 테이블 (예) | 행 수 |
| ------------- | --- |
| `categories` | 8 |
| `customers` | 15 |
| `order_items` | 32 |
| `orders` | 25 |
| `products` | 20 |
| `목표달성` | 18 |
| `설계사 수수료 실적` | 12 |
### 업로드 방법
* **Drop CSV, XLSX, Parquet** 드롭 존에 드래그 앤 드롭
* 또는 도구 `import_data_file` 로 에이전트가 자동 로드
* 업로드 즉시 DuckDB 에 테이블 생성 → `analytics.duckdb` 에 영구 저장 (세션 내)
## Indexed Documents 섹션
PDF·DOCX·PPTX 를 **벡터 인덱싱** 하여 에이전트가 시맨틱 검색할 수 있도록 합니다.
### 업로드 방법
* **Drop PDF, DOCX, PPTX** 드롭 존에 드래그 앤 드롭
* **VLM High-Quality Parse** 토글로 파싱 품질 선택
**VLM High-Quality Parse (PDF, DOCX, PPTX)**
* ON: Vision-Language Model 로 레이아웃·표·이미지 캡션까지 정확히 추출. 품질 ↑, 비용·시간 ↑
* OFF: 일반 텍스트 파싱. 품질 ↓, 비용·시간 ↓
스캔본 PDF, 복잡한 표가 있는 재무 보고서 등은 **ON 권장**. 단순 텍스트 문서는 OFF 로도 충분.
## Tools — 11 개 도구
`Select All` 또는 개별 체크로 활성화 (`0/11 enabled` 표시).
### 정형 데이터 (Tables) 도구 6 종
| 도구 | 용도 |
| ---------------------- | ------------------------------------- |
| **import\_data\_file** | CSV / XLSX / Parquet → DuckDB 테이블로 로드 |
| **list\_tables** | 등록된 테이블 목록 |
| **get\_table\_schema** | 컬럼·타입 정보 조회 |
| **execute\_query** | DuckDB SQL 실행 (SELECT / JOIN / 집계 등) |
| **get\_table\_sample** | 상위 N 행 샘플 |
| **drop\_table** | 테이블 삭제 |
### 비정형 문서 (Documents) 도구 5 종
| 도구 | 용도 |
| ---------------------------- | --------------------------------- |
| **import\_document\_vlm** | VLM 기반 **고품질** 문서 인덱싱 (표·레이아웃 보존) |
| **import\_document** | 일반 텍스트 인덱싱 |
| **search\_documents** | 인덱싱된 문서 벡터 검색 |
| **list\_indexed\_documents** | 인덱싱 완료된 문서 목록 |
| **delete\_document** | 인덱스 삭제 |
**도구 선택 전략**
* **분석만 필요** → `list_tables` · `get_table_schema` · `execute_query` · `get_table_sample`
* **데이터 로드 자동화** → + `import_data_file`
* **RAG 용 문서 검색** → `import_document_vlm` · `search_documents` · `list_indexed_documents`
* **안전 모드** → `drop_table` · `delete_document` 비활성화로 삭제 차단
## 활용 예시
`customers.csv` · `orders.csv` · `order_items.csv` 를 Tables 드롭 존에 투입.
`주문 수 상위 5명 고객을 이름과 함께 알려줘`
에이전트가 `list_tables` → `get_table_schema` → `execute_query`:
```sql theme={null}
SELECT c.name, COUNT(o.id) AS order_count
FROM customers c
JOIN orders o ON o.customer_id = c.id
GROUP BY c.name
ORDER BY order_count DESC
LIMIT 5
```
표 형태로 요약 + 필요 시 차트 생성 ([Image Generation](/agent-chat/toolbar/image-gen)) 또는 리포트 저장 ([Word](/agent-chat/toolbar/word)).
## 아키텍처
| 요소 | 값 |
| --------- | ------------------------------------------------------------- |
| **엔진** | DuckDB (인메모리 + 파일 지속성) |
| **저장 파일** | `analytics.duckdb` (테이블) · `documents.duckdb` (벡터 인덱스) |
| **경로** | 세션의 [Temp Files](/agent-chat/toolbar/temp-files) Root |
| **임베딩** | 테넌트에 등록된 Dense 모델 (예: `qwen/qwen3-embedding-8b`) |
| **VLM** | Vision/Layout Parser — [Billing → Document Parsing](/billing) |
## 운영 주의
* **세션 단위 데이터** — Analytics 테이블·인덱스는 세션과 함께 사라질 수 있습니다. 영구 보관 대상이면 [Storage](/agent-chat/toolbar/storage) 로 이관하거나, 결과물을 Temp Files 에서 다운로드.
* **VLM 파싱 비용** — 고품질 파싱은 페이지당 토큰 비용이 큽니다. 수십 페이지 이상 문서는 사전 견적 (한도·요금: [Billing](/billing)).
* **대용량 테이블** — DuckDB 는 빠르지만 **인메모리** 입니다. 수 GB 이상은 로드 실패·OOM 가능 → 사전에 필터링·샘플링.
* **민감 데이터 SQL 결과 노출** — 개인정보·단가가 포함된 쿼리 결과는 채팅 로그와 Temp Files 에 남습니다. System Prompt 에 마스킹 규칙을 명시하거나 민감 컬럼을 로드하지 않는 방향으로 사전 정리.
* **drop\_table / delete\_document 활성화 주의** — 실수로 제거하면 재업로드 필요.
## 관련 문서
* [Temp Files](/agent-chat/toolbar/temp-files) — DuckDB 파일 위치·다운로드
* [Storage](/agent-chat/toolbar/storage) — 영구 보관 후 에이전트 Table 로 활용
* [대량 문서 인덱싱·요약 레시피](/agent-chat/recipes/bulk-document-summarize) — VLM 파싱을 활용한 배치
* [PostgreSQL 자동화 레시피](/agent-chat/recipes/postgres-sql-automation) — 외부 DB 연결 방식
## UI 구성
| 영역 | 설명 |
| ----------------------------- | ---------------------------------------------------------------- |
| **Tables** 섹션 | 업로드된 정형 테이블 — `Drop CSV, XLSX, Parquet` 드롭 존 |
| **Indexed Documents** 섹션 | 인덱싱된 비정형 문서 — `Drop PDF, DOCX, PPTX` 드롭 존 |
| **VLM High-Quality Parse** 토글 | ON 시 Vision Parser 로 고품질 인덱싱 (표·레이아웃 보존) |
| **Tools** 체크리스트 | 활성화할 도구 선택 (`N/11 enabled`) |
| 상태 라인 | `7 tables • 0 indexed documents` 형태로 요약 |
| 우측 패널 | `Select a table or document to view details` — 선택 시 스키마·샘플·메타 표시 |
## Tables 섹션
업로드된 정형 데이터 테이블 목록. 각 테이블에 **행 수** 가 뱃지로 표시됩니다.
| 테이블 (예) | 행 수 |
| ------------- | --- |
| `categories` | 8 |
| `customers` | 15 |
| `order_items` | 32 |
| `orders` | 25 |
| `products` | 20 |
| `목표달성` | 18 |
| `설계사 수수료 실적` | 12 |
### 업로드 방법
* **Drop CSV, XLSX, Parquet** 드롭 존에 드래그 앤 드롭
* 또는 도구 `import_data_file` 로 에이전트가 자동 로드
* 업로드 즉시 DuckDB 에 테이블 생성 → `analytics.duckdb` 에 영구 저장 (세션 내)
## Indexed Documents 섹션
PDF·DOCX·PPTX 를 **벡터 인덱싱** 하여 에이전트가 시맨틱 검색할 수 있도록 합니다.
### 업로드 방법
* **Drop PDF, DOCX, PPTX** 드롭 존에 드래그 앤 드롭
* **VLM High-Quality Parse** 토글로 파싱 품질 선택
**VLM High-Quality Parse (PDF, DOCX, PPTX)**
* ON: Vision-Language Model 로 레이아웃·표·이미지 캡션까지 정확히 추출. 품질 ↑, 비용·시간 ↑
* OFF: 일반 텍스트 파싱. 품질 ↓, 비용·시간 ↓
스캔본 PDF, 복잡한 표가 있는 재무 보고서 등은 **ON 권장**. 단순 텍스트 문서는 OFF 로도 충분.
## Tools — 11 개 도구
`Select All` 또는 개별 체크로 활성화 (`0/11 enabled` 표시).
### 정형 데이터 (Tables) 도구 6 종
| 도구 | 용도 |
| ---------------------- | ------------------------------------- |
| **import\_data\_file** | CSV / XLSX / Parquet → DuckDB 테이블로 로드 |
| **list\_tables** | 등록된 테이블 목록 |
| **get\_table\_schema** | 컬럼·타입 정보 조회 |
| **execute\_query** | DuckDB SQL 실행 (SELECT / JOIN / 집계 등) |
| **get\_table\_sample** | 상위 N 행 샘플 |
| **drop\_table** | 테이블 삭제 |
### 비정형 문서 (Documents) 도구 5 종
| 도구 | 용도 |
| ---------------------------- | --------------------------------- |
| **import\_document\_vlm** | VLM 기반 **고품질** 문서 인덱싱 (표·레이아웃 보존) |
| **import\_document** | 일반 텍스트 인덱싱 |
| **search\_documents** | 인덱싱된 문서 벡터 검색 |
| **list\_indexed\_documents** | 인덱싱 완료된 문서 목록 |
| **delete\_document** | 인덱스 삭제 |
**도구 선택 전략**
* **분석만 필요** → `list_tables` · `get_table_schema` · `execute_query` · `get_table_sample`
* **데이터 로드 자동화** → + `import_data_file`
* **RAG 용 문서 검색** → `import_document_vlm` · `search_documents` · `list_indexed_documents`
* **안전 모드** → `drop_table` · `delete_document` 비활성화로 삭제 차단
## 활용 예시
`customers.csv` · `orders.csv` · `order_items.csv` 를 Tables 드롭 존에 투입.
`주문 수 상위 5명 고객을 이름과 함께 알려줘`
에이전트가 `list_tables` → `get_table_schema` → `execute_query`:
```sql theme={null}
SELECT c.name, COUNT(o.id) AS order_count
FROM customers c
JOIN orders o ON o.customer_id = c.id
GROUP BY c.name
ORDER BY order_count DESC
LIMIT 5
```
표 형태로 요약 + 필요 시 차트 생성 ([Image Generation](/agent-chat/toolbar/image-gen)) 또는 리포트 저장 ([Word](/agent-chat/toolbar/word)).
## 아키텍처
| 요소 | 값 |
| --------- | ------------------------------------------------------------- |
| **엔진** | DuckDB (인메모리 + 파일 지속성) |
| **저장 파일** | `analytics.duckdb` (테이블) · `documents.duckdb` (벡터 인덱스) |
| **경로** | 세션의 [Temp Files](/agent-chat/toolbar/temp-files) Root |
| **임베딩** | 테넌트에 등록된 Dense 모델 (예: `qwen/qwen3-embedding-8b`) |
| **VLM** | Vision/Layout Parser — [Billing → Document Parsing](/billing) |
## 운영 주의
* **세션 단위 데이터** — Analytics 테이블·인덱스는 세션과 함께 사라질 수 있습니다. 영구 보관 대상이면 [Storage](/agent-chat/toolbar/storage) 로 이관하거나, 결과물을 Temp Files 에서 다운로드.
* **VLM 파싱 비용** — 고품질 파싱은 페이지당 토큰 비용이 큽니다. 수십 페이지 이상 문서는 사전 견적 (한도·요금: [Billing](/billing)).
* **대용량 테이블** — DuckDB 는 빠르지만 **인메모리** 입니다. 수 GB 이상은 로드 실패·OOM 가능 → 사전에 필터링·샘플링.
* **민감 데이터 SQL 결과 노출** — 개인정보·단가가 포함된 쿼리 결과는 채팅 로그와 Temp Files 에 남습니다. System Prompt 에 마스킹 규칙을 명시하거나 민감 컬럼을 로드하지 않는 방향으로 사전 정리.
* **drop\_table / delete\_document 활성화 주의** — 실수로 제거하면 재업로드 필요.
## 관련 문서
* [Temp Files](/agent-chat/toolbar/temp-files) — DuckDB 파일 위치·다운로드
* [Storage](/agent-chat/toolbar/storage) — 영구 보관 후 에이전트 Table 로 활용
* [대량 문서 인덱싱·요약 레시피](/agent-chat/recipes/bulk-document-summarize) — VLM 파싱을 활용한 배치
* [PostgreSQL 자동화 레시피](/agent-chat/recipes/postgres-sql-automation) — 외부 DB 연결 방식